Part 5. Advanced Classification(SVM,NN)
Module 2. 지도학습(분류/회귀)은 이화여자대학교 강제원 교수님이 강의를 하셨고 Module 2에 관한 모든 내용은 LG Aimers 및 이화여자대학교 강제원 교수님으로부터 나왔다.
뒤에 나오는 사진들에서 w와 β는 같은 의미이다.
SVM(Supporter Vector Machine)
SVM은 선형 분류 중 어떤 linear separators가 최적인지 구하는 것에서부터 시작되었다.

SVM을 최적화 하는 과정에서
1. Hard margin SVM(경마진)
2. Soft margin SVM(유연마진)
으로 나눌 수 있다.
먼저
Hard margin SVM

하지만 이 방법의 문제점은실제 데이터에서 두 그룹이 선형으로 완벽히 구분되는 경우가 거의 없다그렇기 때문에 완화변수(slack variable)를 도입하여 soft margin 으로 변환한다.
그래서 Soft margin SVM은
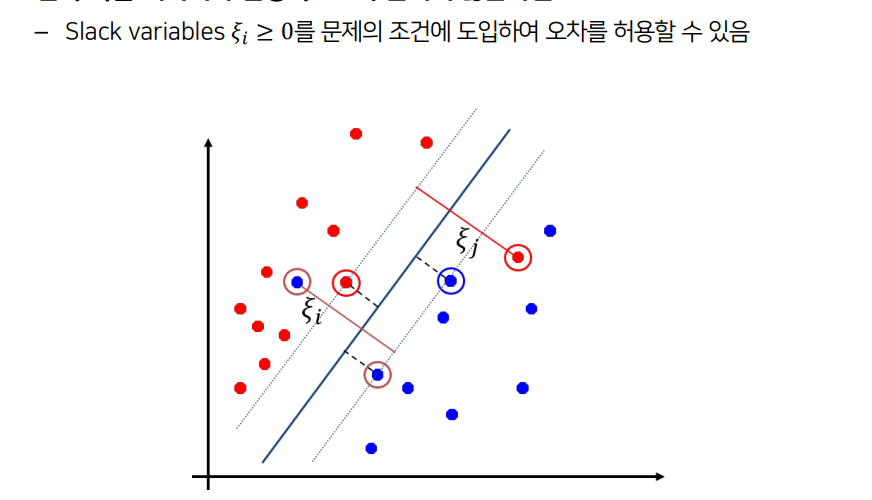
이렇듯 Hard margin SVM으로 못 푸는 문제도 Soft margin SVM을 활용하면 풀 수 있게 된다.
하지만 Soft margin SVM은 ζ의 영향이 고려되지 않아 오차가 얼마나 큰지/작은지 신경쓰지 않는다.
이 문제는 C(초모수)를 통해 해결할 수 있다.
만약 초모수 C가 크면 Margin 폭이 작아져서 overfitting이 발생 한다.
반대로 초모수 C가 작으면 Margin 폭이 커져서 Bias(편이)가 발생한다.

또한 밴드 위에 위치한 자료, 밴드 안의 자료, 잘못 분류 된 자료들은
β(w) 추정에 기여한다.

Non-Linear(비선형) SVM
만약 데이터가 선형적으로 구분하기 어려운 경우에는 어떻게 해결할 것인가?
만약 데이터를 더 높은 차원의 공간으로 확장하여 활용하면 어떨까?
이 질문들은 곧 비선형 SVM의 아이디어가 된다.
새로운 변수를 도입하여 차원을 증가시켜서 비선형 SVM을 구현하지만
적절한 특성 함수 생성의 어려움 + 고차원으로 확장 시 차원의 저주 문제 발생
으로 인해 차원 확장의 어려움을 겪는다.
이때 이 어려움은
Kernel trick으로 해결할 수 있다.
Kernel 함수를 활용하면 직접적인 차원확장 없이 차원을 확장한 효과를 얻게 된다.
즉, transformation(차원확장) 함수 이용 대신 커널함수를 이용하여 SVM을 최적화 하면 된다.
Artificial Neural Network(ANN)
- Non-linear classification model
- DNN의 기본
- Activation function(활성함수)을 이용하여 비선형으로 mapping
- sigmoid 함수는 Neural Network 에서 효과적이지 않다
-> 미분값인 gradient가 작아서 학습량이 작아진다.
-> ReLU, Leaky ReLU 함수 이용 : 미분을 해도 gradient가 1 = 학습량이 줄어들지 않음
Quiz time
1. Support vector machine can be applied to non-linear classification
Answer : O
-> 커널함수를 이용하면 가능하다
2. Neural network is a non-linear classifier given with an activation function, when a neuron produces an output. The performance is always improved with an increasing number of layers.
Answer : X