Part 1. 전통기계학습과 딥러닝에서의 비지도학습
Module 3. 비지도학습은 서울대학교 이원종 교수님이 강의를 하셨고 Module 3에 관한 모든 내용은 LG Aimers 및 서울대학교 이원종 교수님으로부터 나왔다.
전통적 기계학습에서의 비지도학습
1. K-means Clustering
- 가장 널리 사용되는 군집 방법 중 하나
- 특정한 중심값으로 요약되는 K개의 클러스터를 찾음
- 알고리즘의 수렴이 보장되어 있음
- 지역 최적해로 수렴(초기 중심값에 따라 결과가 달라질 수 있음)
- K값을 미리 결정해주어야 함(K-means Clustering의 최대 약점)

K-Means 알고리즘 순서
1. 각 특성 변수의 자료 타입에 따라 자료를 변환한 후 특성 변수를 표준화
2. 학습 데이터에서의 임의의 K개 표본을 뽑아 K개 군집의 중심값으로 놓음
3. 각 관측치를 제곱 유클리디안거리 기준으로 가장 가까운 군집에 편입
4. 각 군집의 평균을 새로 구해 이를 새로운 중심값으로 놓고 3번 다시 실행
5. 각 군집의 member가 변하지 않을 때까지(or 미리 정해진 최대 반복횟수에 도달할 때 까지 4번 반복)
K-Means Clustering의 목표 : 군집의 결과로 얻어지는 손실 함수를 최소화하는 K값을 찾는 것
문제점
-> K가 계속 커지면 손실 함수의 값은 계속 작아지게 된다
--> 하지만 overfitting이 발생
대안 : 손실함수의 감소 속도가 확연히 줄어드는 K를 찾는 것
ex)

비지도학습의 다른 방법
- Hirarchical Clustering

- Density estimation

- PCA : dimension을 줄이기 위한 기법으로 Eigenvalue Decomposition과 동일한 방식
전통적인 머신러닝 기법 : 클러스터링을 한 후 클러스터링 된 결과가 말이 되는지 validation을 꼭 해줘야 함
- Internal Cluster Validation : 스스로 클러스터링 된 데이터를 기반으로 클러스터링의 결과를 평가
- External Cluster Validation : 외부평가에서 클러스터링 결과들은 외부 데이터에 기반해 평가
- Relative Cluster Validation
Validation 기법들
딥러닝에서의 비지도학습
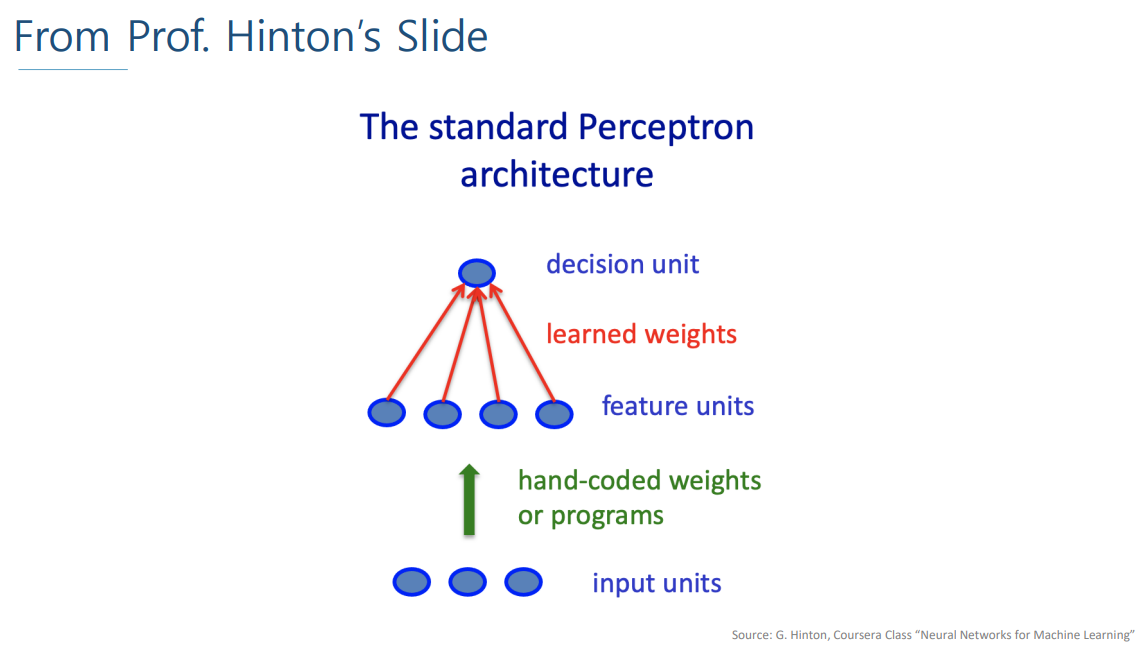
input은 Raw 데이터(오리지널 input 데이터)로 들어가서
hand-coded weight or programs를 통해 Raw 데이터를 정리해서 이용한다.
Feature Engineering VS Representation Learning
• Feature engineering : 전통적 기계학습에서 중요, 딥러닝 목표는 이 부분을 하지 않는 것
- By human(인간이 해야 함)
- Domain knowledge & creativity
- Brainstorming
• Representation leaning : 딥러닝에서의 approach
- By machine(기계 즉, 알고리즘이 해야 함)
- Deep learning knowledge & coding skill (정보에 대한 고민을 하지 않고 딥러닝 모델에 대한 고민을 해야 함)
- Trial and error
Representation
- 알고리즘 입장에서 상당히 중요
- 성능이 잘 나오는데 큰 영향
- 정보를 어떤 식으로 정리/표현할 것인가?
- 어떤 x라는 개념이 있을 때, 수학적인 기호로 표현하는 Rule