안녕하세요!
저번 포스팅에서
저희는 Layer Normalization에 대해서
알아보았어요.
이번 시간엔
코드를 통해
Layer Normalization을 이해해보아요.
저번 Transformer 코드에
Class를 단순히 추가를 해보며
Layer Normalization을
적용시켜 볼거에요.

Multi Head Attention 코드 기억하시나요?
다시 간단히 설명을 해드리겠습니다.
init:
이 메서드에서는 멀티-헤드 어텐션에 필요한 변수와 레이어들을 정의합니다.
embed_dim: 입력 임베딩 차원
num_heads: 사용할 어텐션 헤드의 개수
head_dim: 각 어텐션 헤드의 차원 (전체 임베딩 차원을 헤드 수로 나눈 값)
선형 레이어 :
self.query: 입력에 대한 쿼리 행렬을 생성하기 위한 선형 레이어
self.key: 입력에 대한 키 행렬을 생성하기 위한 선형 레이어
self.value: 입력에 대한 값 행렬을 생성하기 위한 선형 레이어
self.out: 멀티-헤드 어텐션 출력을 결합하기 위한 선형 레이어
forward:
이 메서드는 입력 텐서 x를 받아 멀티-헤드 어텐션을 계산하고 출력 텐서를 반환합니다.
쿼리, 키, 밸류 행렬 생성: 각각의 선형 레이어를 사용하여 입력 텐서 x로부터 쿼리(q), 키(k), 밸류(v) 행렬을 생성합니다.
헤드별 어텐션 수행: 헤드 수만큼의 차원을 추가하여 각 헤드가 독립적으로 어텐션을 수행할 수 있게 합니다.
어텐션 점수 계산 및 정규화: 쿼리 행렬과 키 행렬을 곱하여 어텐션 점수를 계산하고,
소프트맥스 함수를 사용하여 정규화합니다.
어텐션 출력 계산: 정규화된 어텐션 확률과 밸류 행렬을 곱하여 어텐션 출력을 계산합니다.
멀티-헤드 출력 결합: 각 헤드의 어텐션 출력을 결합하여 하나의 출력 텐서를 생성합니다.
최종 출력 계산: 결합된 출력 텐서를 self.out 선형 레이어를 통과시켜 최종 출력 텐서를 얻습니다.
이렇게 얻은 최종 출력 텐서는 멀티-헤드 어텐션 메커니즘을 통해 처리된 결과입니다.
기억이 돌아오셨다면
Layer Normalization을 추가하는 코드를
살펴볼까요?!
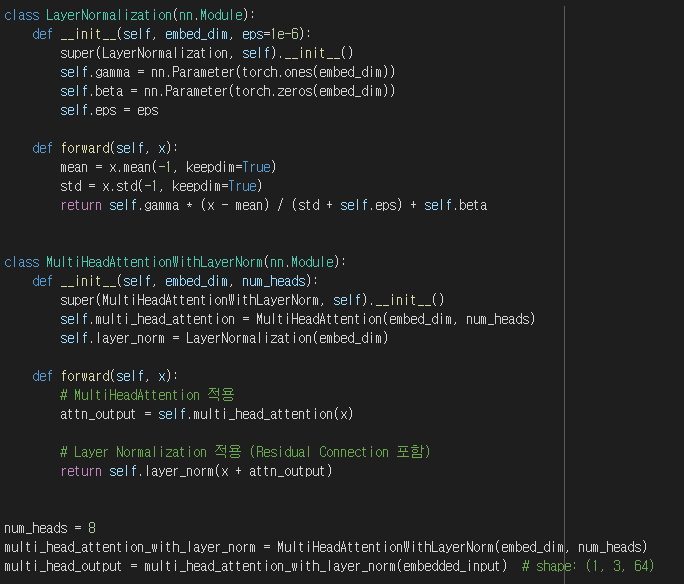
먼저
LayerNormalization Class 에 대해서 설명해드릴게요
이 클래스는 Layer Normalization을 구현하는 모듈로,
Layer Normalization은 신경망의 각 계층에서 활성화를 정규화하는 방법으로,
학습을 안정화하고 수렴을 가속화하는 데 도움이 됩니다.
init:
LayerNormalization 클래스의 생성자입니다.
이 메서드는 두 개의 학습 가능한 매개변수 gamma와 beta를 정의합니다.
gamma는 텐서의 스케일을 조절하고,
beta는 텐서의 평행 이동을 조절합니다.
또한 이 메서드는 작은 상수 eps를 사용하여 수치 안정성을 유지합니다.
forward:
LayerNormalization 모듈의 순전파 메서드입니다.
이 메서드는 입력 텐서 x의 평균(mean)과 표준 편차(std)를 계산하고,
입력 텐서를 정규화한 다음,
학습 가능한 gamma와 beta 매개변수를 사용하여 스케일링 및 시프팅을 수행합니다.
이 LayerNormalization 클래스를 사용하면, 신경망의 계층에서 안정적인 학습을 달성할 수 있습니다.
이 기법은 특히 트랜스포머와 같은 깊은 신경망에서 매우 유용합니다.
그 다음
MultiHeadAttentionWithLayerNorm Class는
멀티 헤드 어텐션(MultiHeadAttention) 레이어와 레이어 정규화(LayerNormalization) 레이어를 결합한 모듈입니다.
init:
embed_dim: 임베딩 차원의 크기입니다.
num_heads: 멀티 헤드 어텐션에서 사용할 헤드의 개수입니다.
multi_head_attention: MultiHeadAttention 객체를 초기화합니다. 입력 텐서에 멀티 헤드 어텐션을 적용할 때 사용됩니다.
layer_norm: LayerNormalization 객체를 초기화합니다. 어텐션 출력에 레이어 정규화를 적용할 때 사용됩니다.
forward:
입력 텐서 x를 받아 멀티 헤드 어텐션과 레이어 정규화를 차례대로 적용한 결과를 반환합니다.
attn_output: 입력 텐서 x에 self.multi_head_attention 레이어를 적용하여 얻은 어텐션 출력입니다.
self.layer_norm(x + attn_output): 어텐션 출력인 attn_output에 입력 텐서 x를 더하여 residual connection을 구현하고
이후 self.layer_norm 레이어를 적용하여 최종 결과를 반환합니다.
여기서 LayerNormalization Class에
gamma, beta, eps에서
자세히 이해가 안되실 분들을 위해
더 자세히 설명해 드리겠습니다.
gamma, beta, 및 eps는 Layer Normalization 과정에서 사용되는 요소들입니다.
각각의 역할과 해당 요소를 사용하지 않았을 때의 장단점을 살펴보겠습니다.
gamma (스케일 매개변수)
역할: 정규화된 텐서의 스케일을 조절합니다.
학습 가능한 매개변수이므로, 네트워크는 적절한 스케일을 학습하여 최적의 성능을 달성할 수 있습니다.
사용하지 않았을 때:
장점: 없음
단점: 네트워크가 스케일을 조절할 수 없기 때문에, 학습 과정에서 최적의 성능을 얻기 어려울 수 있습니다.
beta (편향 매개변수)
역할: 정규화된 텐서의 평행 이동을 조절합니다.
학습 가능한 매개변수이므로,
네트워크는 적절한 평행 이동을 학습하여 최적의 성능을 달성할 수 있습니다.
사용하지 않았을 때:
장점: 없음
단점: 네트워크가 평행 이동을 조절할 수 없기 때문에, 학습 과정에서 최적의 성능을 얻기 어려울 수 있습니다.
eps (안정성을 위한 작은 상수)
역할: 표준편차 계산에서 분모가 0이 되는 것을 방지하기 위해 사용됩니다. eps는 작은 양수 값으로 설정되어,
수치 안정성을 유지하는 데 도움이 됩니다.
사용하지 않았을 때:
장점: 없음
단점: 분모가 0에 가까운 경우, 계산이 불안정해질 수 있습니다.
이로 인해 그래디언트가 폭주할 수 있으며, 신경망의 학습이 불안정해질 수 있습니다.
간단히 말해, gamma와 beta는 Layer Normalization이 최적의 성능을 달성할 수 있도록 돕습니다.
eps는 계산의 안정성을 보장하는 데 사용됩니다.
이러한 요소들을 사용하지 않으면,
네트워크의 성능이 저하되거나 학습이 불안정해질 수 있습니다.
더 완벽한 이해를 위해
예시를 들어봅시다.
normalized_x = [-1.22, 0, 1.22]
이제 gamma와 beta의 역할을 살펴보겠습니다.
gamma (스케일 조절):
정규화된 텐서(normalized_x)에 gamma를 곱하여 각 원소의 스케일을 조절합니다.
예를 들어, gamma가 2라면, 정규화된 텐서의 모든 원소에 2를 곱합니다.
scaled_x = [-2.44, 0, 2.44]
beta (평행 이동):
이제 beta를 사용하여 텐서를 평행 이동합니다.
예를 들어, beta가 1이라면, 스케일 조절된 텐서의 모든 원소에 1을 더합니다.
final_x = [-1.44, 1, 3.44]
결과적으로,
원래 텐서(x)는 정규화, 스케일 조절, 평행 이동을 거쳐 새로운 텐서(final_x)로 변환됩니다.
마지막으로,
eps는 수치 안정성을 위해 사용됩니다.
정규화 과정에서 표준 편차로 나누기 때문에,
표준 편차가 매우 작은 경우에는 0으로 나누는 것을 방지하기 위해 사용됩니다.
일반적으로 eps 값은 매우 작은 양수로 설정됩니다 (예: 1e-6).
이 값은 분모에 더해져서 0으로 나누는 것을 방지합니다.
간단히 말해,
gamma와 beta는 학습 가능한 매개변수로서
Layer Normalization이 최적의 성능을 달성할 수 있도록 돕습니다.
eps는 계산의 안정성을 보장하는 데 사용됩니다.
이러한 요소들을 사용하지 않으면,
네트워크의 성능이 저하되거나 학습이 불안정해질 수 있습니다.
다음 시간엔 Residual Connection에 대해서 알아 보아요!
'AI > Transformer' 카테고리의 다른 글
| Transformer_8(기초부터 심화까지) (0) | 2023.06.28 |
|---|---|
| Transformer_6(기초부터 심화까지) (0) | 2023.06.28 |
| Transformer_5(기초부터 심화까지) (0) | 2023.06.28 |
| Transformer_4(기초부터 심화까지) (0) | 2023.06.28 |
| Transformer_3(기초부터 심화까지) (0) | 2023.06.28 |



